Google Landmark prediction- A Kaggle challenge
Team-Bulldawgs
Team-Bulldawgs implementation of Final Project 5 (Google Landmark Prediction) of Data Science Practicum Spring 2018
Project Description
With the vast amount of landmark images on the Internet, the time has come to think about landmarks globally, namely to build a landmark prediction engine, on the scale of the entire earth.
Develop a technology that can predict landmark labels directly from image pixels, to help people better understand and organize the photo collections.The project challenges to build models that recognize the correct landmark in a dataset of challenging test images. The Kaggle challenge provides access to annotated data which consists of various links to google images along with their respective labeled classes.
Link to the Kaggle competition: https://www.kaggle.com/c/landmark-recognition-challenge
Data-Set
The dataset for this Kaggle competition is available on the following website: https://www.kaggle.com/c/landmark-recognition-challenge/data
File descriptions:
train.csv - the training image set
test.csv - the test set containing the test images for which we may predict landmarks
sample submission.csv - a sample submission file format
There are overall approximately 1.2 million training images with 15,000 unique classes, whereas 0.1 million testing images for labeling and classification.
Requirements
The project requires the following technologies to be installed.
- Instructions to download and install Python can be found here.
- Instructions to download and install Keras can be found here.
- Instructions to download and install Anaconda can be found here.
- Instructions to download and install Tensor Flow can be found here.
- Instructions to download and install OpenCV Library can be found here.
Execution Step
python3 -m bulldawg.__main__ <args>
The following arguments are supported by our model:
- model : Specify the deep learning model to be used Ex: –model=”resnet”, –model=”cnn”
- process : Specify if you want to train or test the dataset and keep empty if train and test both required Ex: –process= “train”, –mode= “test”
- operation : Specify if you want to download and prepare the dataset or keep empty if you want to use the model Ex: –operation=”d_data”
- path : Specify the path where dataset and model will be saved and loaded from Ex: –path=”/home/ubuntu/img.npy”
- num_top_classes : Specify number of most frequency image labels you want to use. Empty if you want to use entire dataset
Ex: –num_top_classes=”400”
Approach
Two Models were implemented:
-
Simple Convolutional Network- More details can be found here
-
Residual Learning for Image Recognition- Resnet50- More details can be found here
Final Output
We predict the landmark and their respective classes for the test data-set and submitted it to kaggle competiton
The Sample Submission format is
id,landmarks
000088da12d664db,8815 0.03
0001623c6d808702,5523 0.85
0001bbb682d45002,5328 0.5
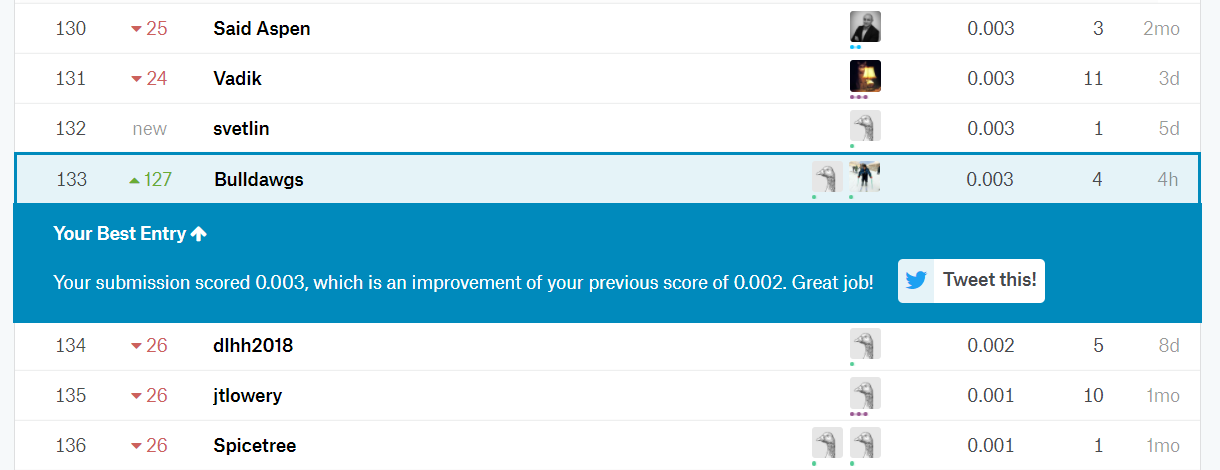
Our Final Kaggle Rank is 134 out of 309 participants [as on 27th April 16.00] with a score of 0.003
Below is the screenshot attached for the same. We got this score by training on just 50 percent of the dataset, so we hope to get a better score by training on entire dataset.
Contributors
See contributor file for more details.
Wiki for this project
I highly recommend checking out our github wiki for more information: https://github.com/ankit-vaghela30/Google-landmark-prediction/wiki
Project report paper
If you want to see NIPS 2016 style paper of this project check here: https://github.com/ankit-vaghela30/Google-landmark-prediction/blob/master/docs/Google_Landmark_Prediction.pdf
link to the project:
link: https://github.com/ankit-vaghela30/Google-landmark-prediction
License
This project is licensed under the MIT License - see the License file for details
Acknowledgments
- This project was completed as a part of the Data Science Practicum 2018 course at the University of Georgia *This work would not have been possible without the support of Dr. Shannon Quinn, [Assistant Professor, University of Georgia Departments of Computer Science and Cellular Biology] who worked actively to provide us with academic time and advice to pursue those goals.
- Other resources used have been cited in their corresponding wiki page.
References
References for this Project:
- https://arxiv.org/pdf/1512.03385.pdf
- https://arxiv.org/abs/1512.03385
- https://github.com/raghakot/keras-resnet
- https://github.com/tensorflow/models/tree/master/research/object_detection
- https://www.kaggle.com/c/landmark-recognition-challenge
- http://pages.cs.wisc.edu/~dyer/cs534-spring10/papers/google_landmark_recognition.pdf
- https://www.youtube.com/watch?v=yDVap0lpYKg